
Implementing a Genomic Data Strategy: A Step-by-Step Guide for Healthcare Organizations
In today's precision medicine landscape, having a comprehensive genomic data strategy is no longer optional for healthcare organizations—it's essential. Yet many institutions struggle with where to begin and how to implement such a strategy effectively. This practical guide outlines a step-by-step approach to developing and implementing a genomic data strategy that delivers tangible value.
Assessing Your Current State
Before implementing any new solution, it's crucial to understand your starting point. Begin with a thorough assessment of your current genomic data landscape:
Genomic Testing Inventory
Which testing platforms are currently in use at your institution?
What is the monthly/annual volume for each test type?
Which departments or clinics order these tests?
How are results currently reported and stored?
Data Flow Mapping
How does genomic data move through your organization?
Where are the handoffs between systems and departments?
Where are the bottlenecks and pain points?
What manual processes are currently required?
Stakeholder Identification
Who interacts with genomic data across your organization?
What are their primary needs and frustrations?
Which leaders need to be involved in the strategy development?
Who will champion the initiative?
Defining Your Vision and Objectives
With a clear understanding of your current state, the next step is defining where you want to go:
Vision Statement
Create a concise statement that describes what success looks like for your organization's genomic data strategy. For example: "To create a unified genomic data ecosystem that enables seamless clinical decision-making, research innovation, and continuous quality improvement."
Specific Objectives
Translate your vision into measurable objectives:
Reduce time from test result to treatment decision by X%
Increase clinical trial enrollment for biomarker-driven studies by Y%
Reduce duplicate genomic testing by Z%
Enable cross-platform queries for research within Q months
Integrate genomic data with the EHR by [specific date]
Value Proposition by Stakeholder
Articulate how the strategy will deliver value to different stakeholders:
For oncologists: Faster access to actionable genomic information
For researchers: Comprehensive data for discovery and validation
For administrators: Improved operational efficiency and cost savings
For patients: Better treatment decisions and trial access
Building Your Implementation Roadmap
With clear objectives established, develop a phased implementation roadmap:
Phase 1: Foundation (Months 1-3)
Select a genomic data normalization solution
Implement for highest-volume testing platforms
Establish data governance processes
Train initial user group (e.g., molecular tumor board)
Measure baseline metrics for future comparison
Phase 2: Expansion (Months 4-6)
Extend normalization to additional testing platforms
Integrate with key systems (e.g., EHR, clinical trial matching)
Expand user training to broader clinical teams
Implement initial reporting and analytics
Begin measuring impact on defined objectives
Phase 3: Optimization (Months 7-12)
Refine workflows based on user feedback
Develop advanced analytics capabilities
Expand to additional use cases (e.g., research queries)
Implement continuous quality improvement processes
Document and share outcomes and lessons learned
Phase 4: Innovation (Year 2+)
Explore advanced applications (e.g., AI/ML)
Consider expanded data types (e.g., imaging, digital pathology)
Develop collaborative research initiatives
Scale successful approaches across the organization
Assembling Your Team
Successful implementation requires the right team with clear responsibilities:
Executive Sponsor
Typically a C-suite leader (CMIO, CIO, CMO)
Provides organizational authority and resources
Removes high-level barriers
Connects project to strategic priorities
Clinical Champion
Respected clinician who understands the value
Advocates with clinical peers
Provides real-world use case expertise
Helps design clinically relevant workflows
Project Manager
Coordinates day-to-day implementation
Tracks milestones and deliverables
Facilitates communication across teams
Identifies and addresses risks
Technical Lead
Oversees technical integration
Coordinates with IT and informatics teams
Ensures data security and privacy
Manages technical vendor relationships
End-User Representatives
Diverse group representing all key user types
Provides feedback on usability and workflows
Participates in testing and validation
Serves as peer trainers and advocates
Overcoming Common Implementation Challenges
Anticipate and plan for these common challenges:
Data Quality Issues
Conduct thorough data profiling early
Implement data cleaning processes
Establish ongoing data quality monitoring
Set realistic expectations about historical data
Integration Complexity
Map all system touchpoints before beginning
Involve interface experts early
Consider phased integration approach
Test thoroughly in non-production environments
Workflow Disruption
Involve end-users in workflow design
Implement changes incrementally when possible
Provide robust training and support
Measure and communicate early wins
Stakeholder Resistance
Clearly articulate "what's in it for me" for each group
Identify and address concerns proactively
Showcase early successes and improvements
Leverage peer champions for adoption
Resource Constraints
Develop clear business case with ROI projections
Consider phased approach to spread investment
Leverage vendor implementation resources
Identify opportunities to reallocate existing resources
Measuring Success and Ensuring Sustainability
Implementation is just the beginning—measuring impact and ensuring sustainability are crucial:
Key Performance Indicators
Establish metrics in these categories:
Clinical impact (e.g., time to treatment decision)
Operational efficiency (e.g., MTB preparation time)
Financial outcomes (e.g., reduced duplicate testing)
User satisfaction (e.g., clinician feedback scores)
Technical performance (e.g., system uptime, query response time)
Continuous Improvement Process
Schedule regular review of metrics and user feedback
Establish process for prioritizing enhancements
Create feedback loops with end-users
Document and share lessons learned
Knowledge Management
Develop comprehensive documentation
Create training materials for new users
Establish super-user program for peer support
Build internal expertise through knowledge transfer
Long-term Governance
Establish ongoing data governance committee
Define processes for adding new data sources
Create policies for data access and usage
Plan for technology evolution and updates
Getting Started: Your First 90 Days
If you're ready to implement a genomic data strategy, here's a practical 90-day plan:
Days 1-30: Assessment and Planning
Complete current state assessment
Identify key stakeholders and form core team
Define vision and objectives
Begin vendor evaluation if applicable
Days 31-60: Solution Selection and Preparation
Select genomic data normalization solution
Develop detailed implementation plan
Establish baseline metrics
Prepare technical environment
Begin initial user training
Days 61-90: Initial Implementation
Implement solution for 1-2 key testing platforms
Deploy to limited user group (e.g., MTB)
Gather feedback and make adjustments
Document early wins and challenges
Develop plan for phase 2 expansion
Remember that implementing a genomic data strategy is a journey, not a destination. The healthcare organizations that succeed are those that approach it methodically, demonstrate value incrementally, and build a foundation for continuous improvement and innovation.
Schedule a demo to learn more about how Frameshift can help your organization implement an effective genomic data strategy that delivers tangible value for clinicians, researchers, administrators, and most importantly, patients.
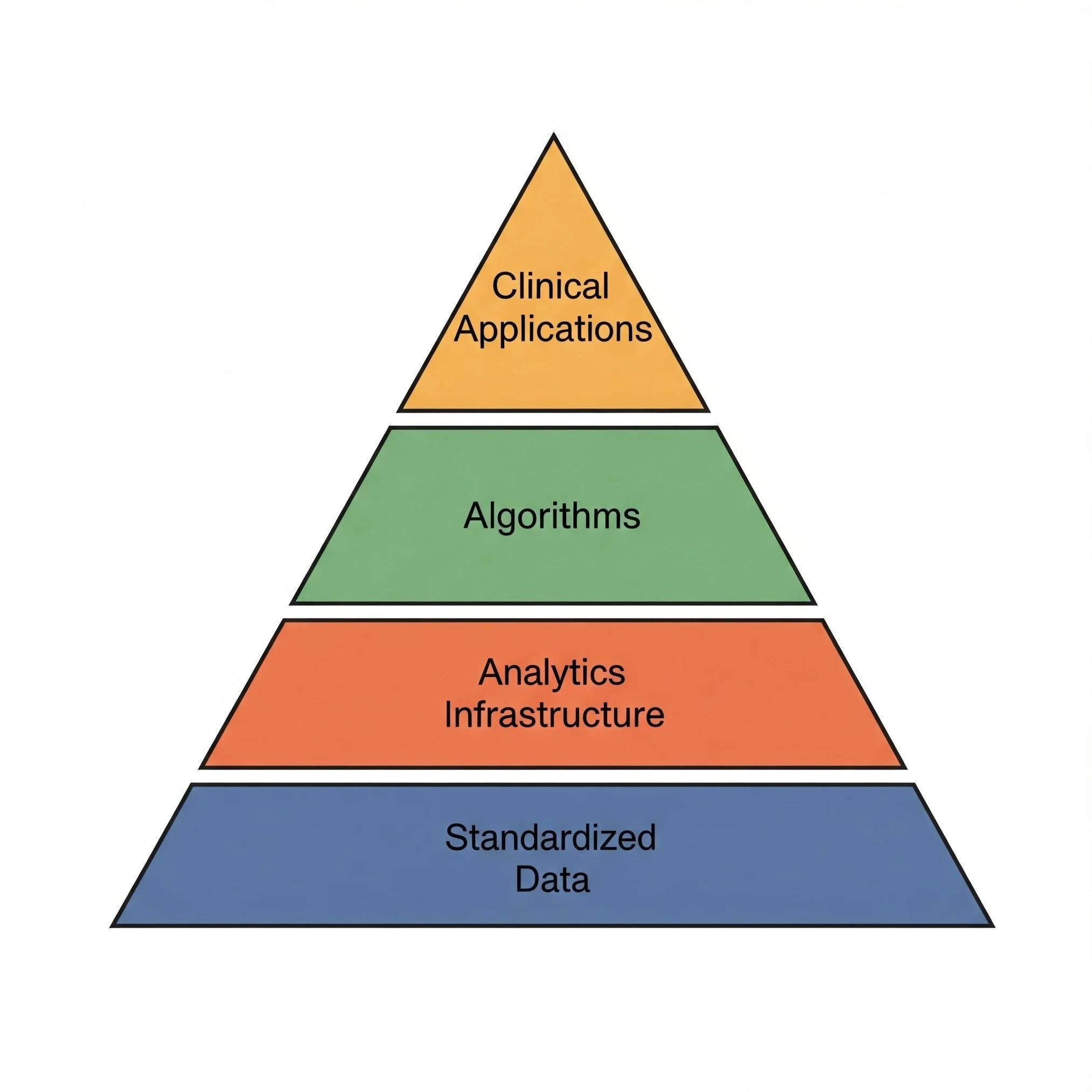
The Future of Precision Oncology: How Data Standardization Enables AI and Machine Learning
In the rapidly evolving landscape of precision oncology, artificial intelligence (AI) and machine learning (ML) promise to transform how we interpret genomic data and make treatment decisions. Yet many institutions discover a critical roadblock when implementing these advanced technologies: the quality and consistency of their underlying data. Let's explore how genomic data standardization creates the essential foundation for successful AI/ML applications in cancer care.
The AI Promise and the Data Reality
The potential applications of AI and machine learning in precision oncology are extraordinary:
Predicting which patients will respond to specific therapies
Identifying novel biomarkers of treatment response or resistance
Discovering unexpected correlations between genomic profiles and outcomes
Generating real-world evidence to complement clinical trial data
Supporting complex treatment decisions with evidence-based recommendations
However, many institutions encounter a sobering reality when they attempt to implement these technologies: their genomic data isn't ready for AI.
Why AI/ML Requires Standardized Data
Artificial intelligence and machine learning algorithms are powerful, but they have specific data requirements that make standardization essential:
Consistency is Critical
AI systems learn by identifying patterns across large datasets. When the same genomic finding is labeled differently across testing platforms (e.g., "amplification" vs. "copy number gain" vs. "increased copy number"), algorithms struggle to recognize these as the same phenomenon, leading to fragmented learning and inaccurate predictions.
Volume Drives Value
The power of AI increases with data volume. When genomic data exists in incompatible formats, institutions effectively have smaller datasets for each format rather than one large, unified dataset. Standardization allows algorithms to learn from all available data, dramatically improving their performance.
Historical Data Unlocks Insights
Many valuable AI applications involve correlating genomic profiles with treatment outcomes over time. Without standardized data that can be analyzed longitudinally, these applications remain out of reach.
Feature Engineering Depends on Quality
Effective AI models rely on well-defined "features" (input variables). Inconsistent genomic data makes feature engineering difficult or impossible, limiting the sophistication of possible models.
The Standardization-AI Virtuous Cycle
When institutions implement proper genomic data standardization, they enable a virtuous cycle of AI/ML development and improvement:
Data Standardization: Genomic data from all sources is normalized into consistent formats and terminology
Initial AI Applications: Basic models can be developed using clean, unified data
Insight Generation: These models produce insights that drive clinical value
Expanded Data Collection: Success drives more comprehensive data collection
Advanced AI Development: Larger, richer datasets enable more sophisticated models
Continuous Improvement: The cycle continues, with each iteration delivering greater value
Real-World AI Applications Enabled by Standardized Data
Let's explore some specific AI/ML applications that become possible with properly standardized genomic data:
Treatment Response Prediction
By analyzing patterns across thousands of patients, AI can help predict which treatments are most likely to benefit a specific patient based on their comprehensive molecular profile.
*Standardization Requirement*: Consistent representation of genomic alterations and treatment responses across all data sources.
Novel Biomarker Discovery
Machine learning can identify unexpected correlations between genomic patterns and treatment outcomes, potentially revealing new biomarkers that wouldn't be apparent through traditional analysis.
*Standardization Requirement*: Unified data format that allows algorithms to consider all genomic features simultaneously, regardless of testing platform.
Resistance Mechanism Identification
AI can analyze pre- and post-treatment genomic profiles to identify patterns associated with treatment resistance, potentially informing strategies to overcome or prevent resistance.
*Standardization Requirement*: Consistent longitudinal data that allows accurate comparison of genomic changes over time.
Real-World Evidence Generation
Machine learning can analyze outcomes across large patient populations to generate real-world evidence about biomarker prevalence, co-occurrence patterns, and treatment effectiveness.
*Standardization Requirement*: Normalized data that enables accurate aggregation and comparison across the entire patient population.
Clinical Decision Support
AI can integrate genomic data with other clinical information to provide evidence-based treatment recommendations, prioritizing options based on the specific patient's characteristics.
*Standardization Requirement*: Structured, normalized genomic data that can be reliably integrated with other clinical data sources.
The Future: From Descriptive to Prescriptive Analytics
As genomic data standardization becomes more sophisticated and widespread, we'll see a progression in AI/ML applications:
Descriptive Analytics (What happened?)
Reporting on genomic testing patterns and findings
Tracking biomarker prevalence and changes over time
Diagnostic Analytics (Why did it happen?)
Understanding correlations between genomic profiles and outcomes
Identifying factors that influence treatment response
Predictive Analytics (What will happen?)
Forecasting individual patient responses to specific therapies
Predicting disease progression based on molecular characteristics
Prescriptive Analytics (What should we do?)
Recommending optimal treatment sequences for specific genomic profiles
Suggesting combination approaches to address complex molecular patterns
Identifying ideal clinical trial matches based on comprehensive patient data
Each step in this progression requires increasingly sophisticated data standardization and integration.
Building Your AI-Ready Data Foundation
If your institution is considering implementing AI/ML applications in precision oncology, start by assessing your data foundation:
Evaluate Current State: How consistent is your genomic data across testing platforms? Can you easily query across all sources?
Implement Standardization: Before investing heavily in AI tools and expertise, ensure your genomic data is normalized into consistent formats and terminology.
Start Small: Begin with focused AI projects that deliver tangible value while you continue to improve your data foundation.
Build Cross-Functional Teams: Successful healthcare AI requires collaboration between clinicians, data scientists, and informatics professionals.
Plan for Scale: Design your data infrastructure to accommodate growing volumes and new data types as your AI initiatives expand.
The institutions that will lead in AI-driven precision oncology aren't necessarily those with the most sophisticated algorithms, but those with the cleanest, most comprehensive standardized data.
Schedule a demo to learn more about how Frameshift can help your institution build the standardized genomic data foundation necessary for successful AI and machine learning applications in precision oncology.

Beyond the Lab: How Genomic Data Normalization Improves Patient Outcomes
In the world of precision oncology, we often focus on the technical aspects of genomic testing and data management. But ultimately, what matters most is how these technologies impact real patients facing cancer diagnoses. Let's explore how genomic data normalization translates into tangible improvements in patient outcomes and care experiences.
The Patient's Journey Through Precision Oncology
Consider Maria, a 58-year-old woman diagnosed with metastatic lung cancer. Her oncologist orders comprehensive genomic profiling to identify potential targeted therapy options. This single test will generate hundreds of data points about her tumor's molecular characteristics—information that could dramatically alter her treatment path and prognosis.
But what happens to that data after testing? How efficiently it's processed, normalized, and integrated into clinical workflows will directly impact Maria's care journey in several critical ways.
From Data to Decisions: The Patient Impact
When genomic data is properly normalized and accessible, patients experience several tangible benefits:
Faster Time to Treatment
Without normalized data, oncologists may spend days trying to interpret complex genomic reports, consulting colleagues, and manually researching treatment options. With normalized data:
Actionable findings are immediately highlighted
Treatment options are more readily identified
Molecular tumor board reviews happen more efficiently
Time from test result to treatment decision can be reduced
For patients like Maria, this could mean starting an effective targeted therapy days or even weeks sooner—critical time when dealing with aggressive disease.
More Precise Treatment Matching
Normalized genomic data enables more accurate matching of patients to appropriate therapies:
Comprehensive visibility into all potentially actionable alterations
Consistent interpretation of variant significance across testing platforms
Better identification of complex biomarkers that may span multiple genes
More reliable matching to FDA-approved therapies and clinical trials
Reduced Treatment Delays and Complications
When genomic data is fragmented or inconsistently interpreted, patients may experience:
Delays while additional testing is ordered to clarify findings
Inappropriate therapy selections based on incomplete information
Missed opportunities for combination approaches
Unnecessary side effects from less targeted treatments
Normalized data helps avoid these pitfalls by providing a complete, consistent view of the patient's genomic profile.
Improved Access to Clinical Trials
For many cancer patients, clinical trials offer access to promising new therapies not yet widely available. Normalized genomic data significantly improves trial access by:
Enabling automatic matching to appropriate trials
Identifying trials at other institutions if local options are exhausted
Allowing trial sponsors to find patients more efficiently
Supporting just-in-time trial activation when eligible patients are identified
More Informed Shared Decision-Making
When oncologists have clear, accessible genomic information, they can have more productive conversations with patients about treatment options:
Clearer explanation of why specific treatments are recommended
Better ability to discuss the evidence supporting different approaches
More transparent discussions about prognosis and expectations
Enhanced patient understanding and engagement in their care
The Longitudinal Impact: Managing Cancer as a Chronic Disease
For many patients, cancer is becoming a chronic disease requiring ongoing management. Normalized genomic data provides critical support throughout this journey:
Tracking Disease Evolution
As patients undergo multiple lines of therapy, their cancer often evolves, developing new mutations that may confer resistance or create new vulnerabilities:
Normalized data makes it easy to compare sequential test results
Changes in genomic profile can be clearly visualized
Emerging resistance mechanisms can be identified earlier
New treatment opportunities can be uncovered as they arise
Coordinating Care Across Settings
Cancer patients often receive care across multiple settings—community practices, academic centers, specialized treatment facilities. Normalized genomic data:
Creates a consistent language for communicating molecular findings
Reduces the need for duplicate testing when patients change providers
Ensures all care team members have the same understanding of genomic results
Supports more coordinated treatment planning
Supporting Survivorship and Monitoring
For patients who achieve remission or stable disease, normalized genomic data continues to provide value:
Informing monitoring strategies based on specific molecular risk factors
Guiding decisions about maintenance therapies
Supporting early intervention if molecular signs of recurrence appear
Connecting patients to appropriate survivorship resources and research
The Future: Personalized Care Pathways
As genomic testing becomes more routine and data normalization more sophisticated, we're moving toward truly personalized care pathways:
AI-assisted treatment recommendations based on comprehensive molecular profiles
Dynamic adjustment of care plans based on real-time molecular monitoring
Integration of genomic data with other health information for holistic care
Patient-facing tools that help individuals understand and engage with their genomic information
Putting Patients at the Center
While the technical aspects of genomic data normalization may seem removed from direct patient care, the reality is that these systems have profound impacts on patient experiences and outcomes.
By implementing solutions that make genomic data more accessible, consistent, and actionable, healthcare organizations can:
Accelerate time to appropriate treatment
Expand access to precision therapies and clinical trials
Reduce unnecessary testing and treatments
Support more informed patient-provider discussions
Ultimately improve survival and quality of life
Schedule a demo to learn more about how Frameshift can help your institution normalize genomic data from any vendor, enabling patient-centered precision oncology that improves outcomes and experiences.

The ROI of Genomic Data Normalization: Making the Business Case for Precision Medicine Infrastructure
In today's healthcare environment, precision medicine initiatives promise to transform patient care through personalized treatment approaches. Yet many institutions struggle to justify the investment in the infrastructure needed to fully leverage genomic data. Let's explore the tangible return on investment (ROI) that comes from implementing genomic data normalization solutions.
Beyond the Science: The Business of Precision Medicine
While the clinical benefits of precision medicine are well-documented, the business case is sometimes less clear. Healthcare leaders often ask:
How do we quantify the value of genomic data normalization?
What tangible returns can we expect from this investment?
How does this technology impact our bottom line?
When will we see results?
These are valid questions in an era of tight budgets and competing priorities. The good news is that genomic data normalization delivers measurable ROI across multiple dimensions.
Quantifiable Returns on Genomic Data Normalization
Let's break down the specific areas where normalized genomic data delivers tangible financial and operational returns:
1. Clinical Trial Revenue Enhancement
When genomic data is normalized and searchable, institutions can:
Identify more eligible patients for industry-sponsored trials
Meet enrollment targets faster, securing milestone payments
Attract more trials due to demonstrated enrollment efficiency
Reduce screening costs by precisely targeting likely eligible patients
2. Operational Efficiency Gains
Normalized genomic data significantly reduces time spent on manual tasks:
Molecular tumor board preparation time reduced
Clinical trial screening time reduced
Pathologist time spent reconciling reports reduced
Oncologist time searching for genomic information reduced
3. Enhanced Reimbursement Opportunities
Proper genomic data management can improve reimbursement in several ways:
Better documentation to support medical necessity for targeted therapies
Increased capture of billable genetic counseling services
Improved prior authorization processes with comprehensive genomic evidence
Support for value-based care metrics related to precision medicine
4. Reduced Duplicate Testing
Without normalized data, institutions often struggle to track what testing has already been performed:
Comprehensive visibility into previous testing reduces unnecessary repeat tests
Estimated savings of thousands of dollars per avoided duplicate comprehensive panel
Additional savings from avoided single-gene or focused panel testing
5. Research Productivity and Grant Funding
Normalized genomic data creates a foundation for research that can drive additional funding:
Increased competitiveness for precision medicine research grants
Accelerated publication output from more efficient data access
Enhanced ability to participate in multi-institutional research consortia
Support for investigator-initiated trials that may lead to industry partnerships
Timeline to ROI: When to Expect Returns
Understanding the timeline for realizing ROI helps with planning and expectation setting:
Immediate Returns (0-3 months):
Operational efficiency gains
Reduced time spent searching for and reconciling genomic data
Enhanced molecular tumor board efficiency
Short-Term Returns (3-6 months):
Improved clinical trial matching and enrollment
Reduced duplicate testing
Better documentation for reimbursement
Medium-Term Returns (6-12 months):
Increased research productivity
Enhanced ability to attract industry partnerships
Improved value-based care metrics
Long-Term Returns (12+ months):
Institutional reputation as a precision medicine leader
Increased patient referrals for molecular-guided therapy
Competitive advantage in grant funding
Potential for novel discoveries with commercial applications
Making the Business Care: Key Metrics to Track
To demonstrate ROI to stakeholders, consider tracking these metrics before and after implementing genomic data normalization:
Efficiency Metrics:
Time spent preparing for molecular tumor boards
Time spent screening patients for clinical trials
Oncologist time spent reviewing genomic information per patient
Number of cases reviewed per molecular tumor board session
Financial Metrics:
Clinical trial enrollment rates and associated revenue
Rate of duplicate genomic testing
Successful reimbursement rate for targeted therapies
Grant funding related to precision medicine initiatives
Quality Metrics:
Time to treatment decision after genomic testing
Percentage of patients matched to targeted therapy or clinical trial
Molecular tumor board recommendation implementation rate
Provider satisfaction with genomic information access
The Competitive Necessity
Beyond the direct ROI, there's an increasingly compelling strategic reason to invest in genomic data normalization: staying competitive in a rapidly evolving healthcare landscape.
Institutions that can effectively leverage their genomic data will:
Attract and retain top clinical and research talent
Secure preferred partnerships with pharmaceutical companies
Maintain competitive advantage in patient recruitment
Position themselves as leaders in precision medicine
Taking the Next Step
If your institution is considering an investment in genomic data normalization, a structured approach to ROI analysis can help build the business case:
Assess your current state and pain points
Identify the specific metrics most relevant to your institution
Establish baseline measurements
Set realistic expectations for returns over time
Implement a solution with clear success metrics
Track and report outcomes to stakeholders
Schedule a demo to learn more about how Frameshift can help your institution build a compelling business case for genomic data normalization and realize tangible returns on your precision medicine investments.
From Data Silos to Searchable Knowledge: How EHR Integration Enhances Genomic Medicine
In today's healthcare environment, electronic health records (EHRs) serve as the central nervous system of clinical operations. Yet when it comes to genomic data, many institutions find that their EHR falls short—creating a disconnect between valuable molecular information and the clinical workflow. Let's explore how proper integration of normalized genomic data with EHRs is transforming patient care and clinical efficiency.
The EHR-Genomics Disconnect
Picture this common scenario: A busy oncologist is seeing a patient with metastatic cancer. The patient has undergone comprehensive genomic profiling, but accessing and interpreting those results requires logging into a separate portal, downloading a PDF report, and manually reviewing pages of complex genomic information—all while the patient is waiting and the clinic schedule is running behind.
This disconnect between genomic data and the EHR creates several challenges:
Workflow Disruption: Clinicians must interrupt their EHR workflow to access genomic information, reducing efficiency and potentially missing important details.
Limited Searchability: PDF reports stored in the EHR as attachments aren't searchable, making it impossible to query across patients or find specific genomic alterations.
Incomplete Clinical Context: Genomic data viewed in isolation from other clinical information lacks the context needed for optimal decision-making.
Documentation Burden: Clinicians often need to manually document key genomic findings in their notes, introducing potential for transcription errors.
Fragmented Patient Records: When genomic data lives outside the primary clinical record, it creates fragmentation that can impact care coordination.
The Transformation: Integrated, Normalized Genomic Data
When genomic data is properly normalized and integrated with the EHR, the clinical experience transforms:
Seamless Workflow: Clinicians can access key genomic information directly within their EHR workflow, without disrupting their clinical process.
Actionable Summaries: Rather than sifting through lengthy reports, clinicians see concise, actionable summaries of the most clinically relevant findings.
Contextual Presentation: Genomic information is presented alongside relevant clinical data, providing the context needed for informed decision-making.
Population Queries: Institutions can run queries across their patient population to identify candidates for specific therapies or clinical trials.
Longitudinal Tracking: Changes in a patient's genomic profile over time can be tracked and visualized, providing insights into disease evolution and treatment response.
Real-World Benefits of EHR-Genomic Integration
The integration of normalized genomic data with the EHR delivers tangible benefits across the healthcare ecosystem
For Clinicians:
Reduced time spent searching for and interpreting genomic information
More informed treatment decisions with complete clinical context
Easier identification of clinical trial opportunities for patients
Simplified documentation with structured genomic data
For Patients:
More time for meaningful discussions during appointments
Reduced risk of missed treatment opportunities
More coordinated care across the healthcare team
Potentially faster treatment decisions
For Institutions:
Enhanced ability to leverage genomic data for population health initiatives
Improved compliance with documentation requirements
More efficient use of expensive genomic testing
Better data for quality improvement and research
Beyond Basic Integration: Advanced Applications
Forward-thinking institutions are moving beyond basic genomic data integration to implement more advanced applications:
Clinical Decision Support: Automated alerts can notify clinicians about potential targeted therapy options based on a patient's genomic profile.
Automated Trial Matching: The EHR can automatically flag patients who meet genomic eligibility criteria for open clinical trials.
Outcomes Tracking: Institutions can correlate genomic profiles with treatment responses and outcomes to generate real-world evidence.
Predictive Analytics: With sufficient data, machine learning algorithms can help predict which patients are most likely to benefit from specific molecularly targeted approaches.
Streamlined Reimbursement: Structured genomic data can facilitate more efficient prior authorization and reimbursement processes for targeted therapies.
The Future of EHR-Genomic Integration
As genomic testing becomes more routine in oncology and other specialties, the need for seamless EHR integration will only grow. The future will likely bring:
Expanded Genomic Content: Integration of additional genomic data types, including RNA sequencing, methylation profiling, and immune markers.
Cross-Institutional Sharing: Standardized formats will facilitate sharing of genomic data when patients move between healthcare systems.
Patient Access: Patients will have improved access to their own genomic information through patient portals.
AI-Enhanced Interpretation: Artificial intelligence will help prioritize and contextualize genomic findings for clinicians.
Enhancing Your EHR with Genomic Data
If your institution is struggling with the disconnect between genomic data and your EHR, you're not alone. Many leading healthcare organizations have faced this challenge and found that implementing a normalization and integration solution transformed their clinical workflows.
By enhancing your EHR with normalized, structured genomic data, you can:
Improve clinical efficiency and reduce documentation burden
Enhance treatment decision-making with contextual genomic information
Enable population-level queries and insights
Build a foundation for advanced clinical decision support
Ultimately deliver better, more precise care to your patients
Schedule a demo to learn more about how Frameshift can help your institution normalize genomic data from any vendor and integrate it seamlessly with your EHR, enhancing clinical workflows and improving patient care.

Maximizing Clinical Trial Enrollment: How Normalized Genomic Data Connects Patients to Novel Therapies
In the world of oncology, clinical trials represent hope—offering patients access to cutting-edge treatments while advancing our collective understanding of cancer. Yet many institutions struggle with a persistent challenge: efficiently matching patients to appropriate trials based on their molecular profiles. Let's explore how normalized genomic data is transforming this process and helping more patients access potentially life-changing therapies.
The Clinical Trial Matching Challenge
Consider this common scenario: Your institution is participating in dozens of clinical trials, many with specific molecular eligibility criteria. You have thousands of patients with genomic testing results from various platforms. In theory, this should create the perfect environment for connecting patients to trials. In practice, however, the process is often frustratingly inefficient.
Without standardized data, finding eligible patients becomes a manual, time-consuming process. Clinical trial coordinators might spend hours sifting through reports with different formats and terminology, trying to identify patients with specific genomic alterations. Oncologists, overwhelmed with patient care responsibilities, may miss potential trial opportunities simply because the information isn't readily accessible.
The result? Trials struggle to meet enrollment targets, and patients miss out on potentially beneficial treatments.
Real-World Enrollment Barriers
Institutions facing genomic data standardization challenges typically experience several obstacles to efficient trial enrollment:
Manual Screening Inefficiency: Trial coordinators spend excessive time manually reviewing individual reports rather than running simple queries across the patient population.
Inconsistent Terminology: What one vendor calls a "fusion" another might label a "rearrangement," making systematic searches difficult.
Missed Opportunities: Patients with eligible genomic profiles may not be identified if their testing was performed on a platform that uses different terminology or formatting.
Delayed Enrollment: The time required to manually screen patients can delay enrollment, potentially causing patients to miss critical treatment windows.
Limited Trial Portfolio: Without efficient matching capabilities, institutions may hesitate to open complex biomarker-driven trials, limiting patient access to innovative therapies.
A clinical trial coordinator at a major cancer center shared: "We were running a trial requiring a specific gene fusion that occurs in about 1-2% of patients. Finding eligible patients felt like searching for a needle in a haystack because we couldn't easily query across all our testing platforms."
Transforming Trial Enrollment with Standardized Data
When genomic data is properly standardized and normalized across testing platforms, the trial matching process transforms:
Automated Patient Identification: Trial coordinators can run simple queries to instantly identify all patients with specific genomic alterations, regardless of which platform performed the testing.
Proactive Matching: New patients can be automatically matched to open trials as soon as their genomic results become available.
Historical Patient Retrieval: Patients tested in the past can be easily identified when new trials open, expanding the pool of potential participants.
Real-Time Enrollment Tracking: Institutions can better monitor potential enrollment pipelines for each trial and adjust recruitment strategies accordingly.
Expanded Trial Portfolio: With efficient matching capabilities, institutions can confidently participate in more biomarker-driven trials, knowing they can identify eligible patients.
The Ripple Effect of Efficient Trial Matching
The benefits of standardized genomic data for clinical trial enrollment extend beyond just filling trial slots:
Patient Access to Innovation: More patients gain access to novel therapies that might not otherwise be available to them.
Accelerated Drug Development: Trials reach enrollment targets faster, potentially speeding the development of new cancer therapies.
Institutional Reputation: Cancer centers known for efficient trial operations become preferred sites for innovative trials, further expanding patient access.
Physician Satisfaction: Oncologists appreciate being able to offer more trial options to their patients without increasing their administrative burden.
Research Insights: As more patients enroll in biomarker-driven trials, researchers gain valuable insights into the relationship between genomic profiles and treatment responses.
The Future of Trial Matching
As clinical trials become increasingly precise in their molecular eligibility criteria, the need for standardized genomic data will only grow. Forward-thinking institutions are implementing solutions that automatically normalize genomic data from all sources, creating a unified resource for trial matching.
This approach doesn't just improve current trial operations—it creates a foundation for more advanced applications, such as:
Predictive Matching: Using historical data to predict which patients are most likely to benefit from specific molecularly targeted therapies.
Multi-site Collaboration: Standardized data facilitates patient referrals between institutions for rare biomarker trials.
Just-in-Time Trial Activation: Institutions can make more informed decisions about which trials to open based on their patient population's genomic profiles.
Integrated Decision Support: Trial eligibility can be automatically flagged within clinical workflows, making it easier for oncologists to discuss options with patients.
Enhancing Your Trial Program
If your institution is struggling to efficiently match patients to biomarker-driven clinical trials, you're not alone. Many leading cancer centers have faced this challenge and found that implementing a standardization solution transformed their trial operations.
By giving your clinical trial team access to normalized, searchable genomic data across your entire patient population, you can:
Identify more eligible patients for each trial
Reduce the administrative burden on trial coordinators and oncologists
Expand your portfolio of precision medicine trials
Accelerate enrollment timelines
Ultimately provide more patients with access to innovative therapies
Schedule a demo to learn more about how Frameshift can help your institution standardize genomic data from any vendor, enabling more efficient clinical trial matching that benefits both patients and research progress.

Bridging the Gap: How Molecular Tumor Boards Thrive with Standardized Genomic Data
In the evolving landscape of precision oncology, Molecular Tumor Boards (MTBs) have emerged as a critical forum where multidisciplinary experts collaborate to interpret complex genomic findings and translate them into actionable treatment plans. Yet many MTBs face a significant challenge: making sense of disparate genomic data from multiple testing platforms. Let's explore how data standardization is transforming these collaborative discussions and improving patient care.
The Molecular Tumor Board Challenge
Picture this scenario: An oncologist presents a complex case to your institution's Molecular Tumor Board. The patient has metastatic cancer and has undergone multiple genomic tests over time—a solid tumor panel from one vendor, a liquid biopsy from another, and perhaps RNA sequencing from your in-house lab. Each report uses different formats, terminology, and reference sequences.
As the discussion unfolds, valuable time is spent reconciling these differences rather than focusing on clinical interpretation and treatment recommendations. Pathologists flip between reports trying to determine if variants are truly the same. Oncologists struggle to track changes across time points. Researchers can't easily connect the findings to potential clinical trials.
This isn't just inefficient—it can impact the quality of care patients receive.
The Real-World Impact on MTB Effectiveness
Molecular Tumor Boards facing data standardization challenges typically experience several pain points:
Time Wasted on Data Reconciliation: MTB members spend precious meeting time trying to align information from different reports rather than discussing clinical implications.
Inconsistent Interpretation: Without standardized data, the same genomic finding might be interpreted differently depending on which report is being referenced.
Incomplete Historical Context: Tracking a patient's genomic evolution over time becomes difficult when sequential tests use different formats and terminology.
Missed Trial Opportunities: Without normalized data, matching patients to appropriate clinical trials becomes more challenging and error-prone.
Limited Educational Value: The teaching potential of MTBs is diminished when discussions get bogged down in data reconciliation rather than clinical reasoning.
A pathologist who participates in a busy MTB shared: "We were spending the first half of each case just trying to get everyone on the same page about what variants were present. That's not what our clinical experts should be focusing on."
Transforming MTB Discussions with Standardized Data
When genomic data is properly standardized and normalized, MTB discussions transform:
Focus on Clinical Interpretation: With all genomic data presented in a consistent format, MTB members can immediately focus on the clinical significance of findings rather than reconciling differences between reports.
Longitudinal Genomic Context: Standardized data makes it easy to visualize how a patient's genomic profile has evolved over time and in response to treatments.
Efficient Trial Matching: With normalized data, matching patients to appropriate clinical trials based on their molecular profile becomes more systematic and comprehensive.
Enhanced Collaboration: Standardized data creates a common language that facilitates more productive discussions across disciplines.
Streamlined Workflow: Pre-MTB preparation becomes more efficient, allowing for more cases to be reviewed or more thorough discussion of complex cases.
The Collaborative Power of Standardized Data
Consider how standardized genomic data enhances specific aspects of MTB collaboration:
Pathologist-Oncologist Communication: Pathologists can more clearly communicate the significance of genomic findings when everyone is looking at consistently formatted data.
Research Integration: Researchers can more easily connect MTB cases to broader patterns they're observing across the patient population.
Pharmacist Input: Pharmacists can more efficiently identify potential drug interactions or alternative therapies when genomic data is presented consistently.
Genetic Counselor Perspective: Genetic counselors can more readily identify findings with potential germline implications that warrant further investigation.
Fellow and Resident Education: Trainees can focus on learning clinical reasoning rather than getting lost in the complexities of different reporting formats.
The Future of Molecular Tumor Boards
As genomic testing becomes more complex and multi-omic approaches become standard, the need for data standardization will only increase. Forward-thinking institutions are implementing solutions that automatically normalize genomic data from all sources, creating a unified view for MTB discussions.
This approach doesn't just improve current MTB efficiency—it creates a foundation for more advanced applications, such as:
AI-Assisted Case Preparation: Machine learning algorithms can help prioritize and contextualize findings when working with standardized data.
Virtual MTBs: Standardized data facilitates remote collaboration and second opinions from external experts.
Automated Trial Matching: Systems can continuously scan for clinical trial matches based on a patient's normalized genomic profile.
Outcomes Tracking: Institutions can more easily track how MTB recommendations impact patient outcomes when working with standardized data.
Elevating Your Molecular Tumor Board
If your Molecular Tumor Board is struggling with disparate genomic data from multiple testing vendors, you're not alone. Many leading institutions have faced this challenge and found that implementing a standardization solution transformed their MTB discussions.
By giving your MTB access to normalized, consistently presented genomic data, you can:
Focus discussions on clinical interpretation rather than data reconciliation
Improve the efficiency and throughput of your MTB
Enhance collaboration across disciplines
Provide better educational experiences for trainees
Ultimately deliver more precise treatment recommendations for patients
Schedule a demo to learn more about how Frameshift can help your institution standardize genomic data from any vendor, enabling more productive Molecular Tumor Board discussions that drive better patient care.

Unlocking Research Potential: How Standardized Genomic Data Accelerates Discovery
In the fast-paced world of cancer research, time is precious. Every day brings new discoveries about genomic biomarkers, potential therapeutic targets, and clinical trial opportunities. Yet at many institutions, one of the biggest barriers to research progress isn't scientific knowledge—it's data accessibility.
The Hidden Research Bottleneck
Imagine you're a cancer researcher interested in understanding how a specific gene fusion affects treatment response across different tumor types. Your institution has tested thousands of patients over the past few years using various genomic platforms. This wealth of data should be a goldmine for your research, but there's a problem: the data exists in multiple formats, uses inconsistent terminology, and lives in separate systems.
What should be a straightforward database query becomes a manual, time-consuming process of reconciling data from different sources. This isn't just frustrating—it actively slows down research progress and limits the insights that could benefit patients.
Real-World Research Challenges
Researchers at cancer centers and academic institutions face several common challenges when working with non-standardized genomic data:
Limited Sample Sizes: When data can't be easily aggregated across testing platforms, researchers are forced to work with smaller sample sizes, reducing statistical power and limiting the significance of findings.
Selection Bias: If only certain data sources are accessible or easier to work with, researchers may inadvertently introduce selection bias into their studies.
Delayed Discoveries: Manual data reconciliation can add weeks or months to research timelines, delaying potential breakthroughs.
Missed Correlations: Important patterns or correlations may go undetected when data exists in silos that can't be easily connected.
Duplicated Efforts: Without centralized, normalized data, different research teams may unknowingly duplicate efforts to clean and standardize the same datasets.
The Transformation: Standardized Data Unlocks Research Potential
When genomic data is standardized and normalized across sources, the research landscape transforms:
Accelerated Discovery: Researchers can quickly test hypotheses across larger datasets, accelerating the pace of discovery.
Novel Insights: By connecting previously siloed data, researchers can identify patterns and correlations that weren't visible before.
Democratized Access: Data standardization makes genomic information accessible to a broader range of researchers, not just those with specialized data science skills.
Enhanced Collaboration: Standardized data facilitates collaboration across departments and even between institutions, as researchers can more easily share and compare findings.
Longitudinal Analysis: Researchers can track genomic changes over time and correlate them with treatment responses and outcomes.
From Theory to Practice: Standardization in Action
Consider how standardized genomic data can transform specific research scenarios:
Biomarker Discovery: Researchers can quickly identify potential new biomarkers by analyzing patterns across thousands of patient samples, regardless of which testing platform was used.
Resistance Mechanisms: By analyzing pre- and post-treatment genomic profiles across a large patient population, researchers can identify potential mechanisms of treatment resistance.
Rare Variant Analysis: Standardized data makes it possible to identify and study rare genomic variants that might only appear in a handful of patients across the entire database.
Real-World Evidence Generation: Researchers can generate real-world evidence about biomarker prevalence, co-occurrence patterns, and treatment outcomes to complement clinical trial data.
The Future of Genomic Research
As multi-omic testing becomes more common and the volume of genomic data continues to grow exponentially, the value of standardization will only increase. Forward-thinking institutions are investing in solutions that automatically normalize genomic data as it enters their systems, creating a continuously growing resource for research.
This approach doesn't just benefit current research—it creates a foundation for future investigations, including those using advanced techniques like machine learning and artificial intelligence, which rely heavily on clean, standardized data.
Empowering Your Research Team
If your researchers are struggling with disparate genomic data sources, you're not alone. Many leading institutions have faced this challenge and found that implementing a standardization solution was transformative for their research programs.
By giving your researchers access to normalized, searchable genomic data across your entire patient population, you can:
Accelerate the pace of discovery
Enable more comprehensive and powerful analyses
Free up valuable researcher time for scientific thinking rather than data wrangling
Facilitate collaboration across departments and with external partners
Build a foundation for future research innovations
Schedule a demo to learn more about how Frameshift can help your institution standardize genomic data from any vendor, enabling powerful research capabilities that drive scientific discovery and, ultimately, improve patient care.

The Challenge of Disparate Genomic Data in Oncology: How Normalization Drives Better Insights
In the world of oncology, genomic data has become a cornerstone of precision medicine. From identifying targetable mutations to matching patients with clinical trials, molecular testing has revolutionized how we approach cancer treatment. But there's a challenge that many cancer centers and research institutions face daily: the data coming from different genomic testing vendors is anything but standardized.
In the world of oncology, genomic data has become a cornerstone of precision medicine. From identifying targetable mutations to matching patients with clinical trials, molecular testing has revolutionized how we approach cancer treatment. But there's a challenge that many cancer centers and research institutions face daily: the data coming from different genomic testing vendors is anything but standardized.
When Data Speaks Different Languages
Imagine you're an oncologist reviewing molecular testing results for three different patients. One report comes from Foundation Medicine, another from Guardant Health, and a third from your in-house next-generation sequencing lab. Each report uses slightly different terminology, formats, and reference sequences. What one vendor calls a "pathogenic variant," another might label as "likely pathogenic" or simply "actionable."
This isn't just a minor inconvenience—it's a significant barrier to leveraging the full potential of genomic data across your patient population.
The Real-World Impact of Data Inconsistency
These inconsistencies create several practical challenges:
Inefficient Manual Review: Clinicians and researchers spend valuable time manually interpreting and reconciling differences between testing platforms instead of focusing on patient care.
Missed Opportunities: Without normalized data, it's difficult to query across your entire patient population. This means potential matches for clinical trials or newly approved targeted therapies might be overlooked simply because of terminology differences.
Limited Research Insights: When data exists in silos or inconsistent formats, extracting meaningful patterns or conducting retrospective analyses becomes exponentially more difficult.
Collaboration Barriers: Molecular tumor boards and multidisciplinary teams struggle to efficiently discuss cases when everyone is looking at differently formatted data.
A pathologist at a leading cancer center recently shared with us: "Before we standardized our genomic data, we were essentially operating with one hand tied behind our back. We knew the valuable insights were there in our data, but accessing them consistently was nearly impossible."
The Normalization Solution
Data normalization is the process of transforming disparate genomic data into a consistent, standardized format. This isn't just about making data look prettier—it's about making it truly useful and actionable.
Effective normalization includes:
Standardizing Terminology: Creating consistency in how variants, genes, and clinical significance are described.
Unifying Reference Sequences: Ensuring all genomic coordinates refer to the same reference genome.
Harmonizing Clinical Annotations: Aligning interpretations of pathogenicity and clinical relevance.
Integrating Metadata: Preserving important context about testing methodology and limitations.
The Downstream Benefits
When genomic data is properly normalized, the benefits ripple throughout the organization:
Enhanced Clinical Decision Support: Oncologists can quickly access and interpret molecular information, regardless of which vendor performed the testing.
Powerful Population Queries: With standardized data, you can easily search across your entire patient population to identify candidates for clinical trials or newly approved therapies.
Research Acceleration: Researchers can analyze trends, outcomes, and correlations across a unified dataset, potentially leading to new discoveries.
Efficient Collaboration: Molecular tumor boards can focus on clinical interpretation rather than reconciling data format differences.
Improved Patient Outcomes: Ultimately, when the right treatment reaches the right patient at the right time, outcomes improve.
Real-World Success
The Duke Cancer Institute implemented a genomic data normalization solution that transformed how they utilize molecular testing information. By standardizing data from multiple vendors, they were able to:
Quickly identify patients with specific molecular signatures for clinical trial enrollment
Streamline their molecular tumor board workflow
Enable researchers to conduct more comprehensive retrospective analyses
Improve the matching of patients to targeted therapies
The Path Forward
As genomic testing continues to evolve and expand, the challenge of disparate data will only grow. New testing methodologies, additional biomarkers, and emerging vendors will add to the complexity.
Forward-thinking institutions are addressing this challenge head-on by implementing solutions that automatically normalize genomic data as it enters their systems. This proactive approach ensures that all molecular information—regardless of source—is immediately usable for clinical decision-making, research, and collaboration.
The future of precision oncology depends not just on generating more genomic data, but on making that data consistently accessible and actionable across the entire care team.
Taking the Next Step
If your institution is struggling with disparate genomic data from multiple testing vendors, you're not alone. Many leading cancer centers have faced this challenge and found that implementing a normalization solution was a game-changer for their precision medicine programs.
Schedule a demo to learn more about how Frameshift can help your institution normalize genomic data from any vendor, enabling powerful searching and collaborative case discussion that drives better patient outcomes.